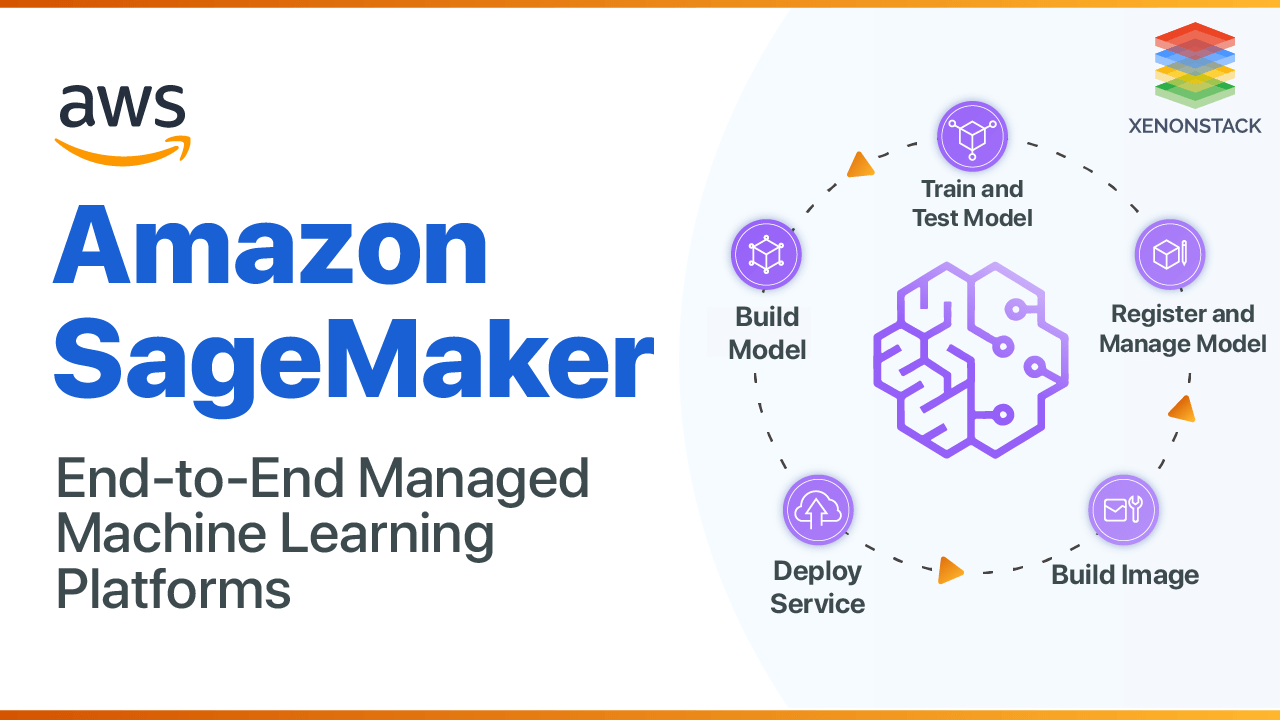
Amazon SageMaker: In the evolving realm of machine learning (ML), enterprises and individuals alike are continuously looking for tools that simplify workflows and enhance scalability. Amazon SageMaker, a fully managed service offered by AWS, has emerged as a powerful solution for building, training, and deploying various machine learning models at scale. With its modular capabilities and integration with other AWS services, SageMaker enables data scientists to streamline the ML lifecycle from data preparation and all the way to model deployment.
For students pursuing a data science course, understanding how to leverage tools like Amazon SageMaker is crucial for practical success in the industry. This article explores the features, architecture, benefits, and applications of Amazon SageMaker in end-to-end machine learning.
What is Amazon SageMaker?
Amazon SageMaker is a reliable cloud-based machine learning (ML) platform that allows developers and data scientists to create, train, and deploy ML models quickly and efficiently. Launched in 2017 by Amazon Web Services, it reduces the complexity as well as time associated with building ML pipelines by offering a suite of pre-built tools and services.
Key components of SageMaker include:
- SageMaker Studio: A reliable integrated development environment (IDE) for ML.
- SageMaker Autopilot: Automatically builds and trains models.
- SageMaker Ground Truth: Assists with data labeling.
- SageMaker Experiments: Helps track, compare, and evaluate models.
- SageMaker Pipelines: Enables CI/CD for ML workflows.
Understanding and utilizing these components is an essential part of a modern course in Hyderabad, especially as cloud platforms dominate the AI industry.
Data Preparation with SageMaker
Before any model is trained, proper data preprocessing and transformation are necessary. SageMaker supports various data sources, including Amazon S3, Redshift, and even on-premise storage. Users can clean, analyze, and transform data using Jupyter notebooks integrated within SageMaker Studio.
Features like built-in data wrangling tools, support for distributed data processing, and integration with AWS Glue make SageMaker a reliable environment for data engineering tasks. These features are aligned with the expectations of hands-on modules in a comprehensive course.
Model Building and Training
Once data is ready, SageMaker offers multiple ways to build models:
- Built-in Algorithms: Choose from pre-optimized algorithms for tasks like classification, regression, clustering, and recommendation systems.
- Bring Your Own Model (BYOM): Upload and train custom models using popular frameworks such as TensorFlow, PyTorch, or Scikit-learn.
- Hugging Face Integration: Train and fine-tune transformer models with minimal configuration.
Model training can be done using SageMaker’s powerful managed infrastructure that supports distributed training, GPU acceleration, and automatic model tuning.
Students enrolled in a course in Hyderabad are encouraged to get hands-on experience with these frameworks and practices, making SageMaker an invaluable tool for modern ML education.
Model Evaluation and Tuning
After training a model, it must be evaluated to ensure its performance on unseen data. SageMaker provides capabilities such as:
- Built-in evaluation metrics for classification, regression, and clustering.
- Automatic Model Tuning (Hyperparameter Optimization) that tests multiple configurations to find the best fit.
- SageMaker Debugger and Model Monitor to diagnose training issues and monitor deployed models.
These tools enable continuous improvement and reliability, aligning well with the goals of students participating in advanced course curricula.
Deployment with SageMaker
One of SageMaker’s most impressive features is its simplified model deployment capability. You can deploy models as:
- Real-time Endpoints: For real-time inference with auto-scaling.
- Batch Transform Jobs: For running predictions on large datasets.
- Multi-model Endpoints: Serve multiple models from a single endpoint, reducing costs.
SageMaker also provides model versioning and rollback features, which are important for managing models in production environments. These aspects are particularly relevant to those enrolled in a coursein Hyderabad, where deploying scalable solutions is a core learning objective.
Security and Compliance
SageMaker complies with major standards such as GDPR, HIPAA, and ISO. It also offers features like:
- Role-based Access Control (RBAC) using AWS IAM
- Data encryption at rest and in transit
- Private VPC support for secure networking
These features are critical for industries handling sensitive information, and understanding them adds value for learners in any course aiming to work in regulated sectors like finance or healthcare.
Integration with the AWS Ecosystem
Amazon SageMaker doesn’t work in isolation. It integrates seamlessly with other AWS services:
- AWS Lambda: For serverless data processing.
- AWS Step Functions: To orchestrate ML workflows.
- Amazon Athena and Redshift: For querying and analytics.
- AWS CloudWatch: For monitoring model performance.
This ecosystem empowers developers to create robust and scalable ML pipelines. Mastery of this integration is essential for students taking a coursein Hyderabad, ensuring they are ready for real-world applications.
Use Cases and Industry Applications
- Retail: Personalized product recommendations and demand forecasting.
- Healthcare: Predictive diagnostics and patient risk scoring.
- Finance: Fraud detection and credit scoring.
- Manufacturing: Predictive maintenance and quality control.
- Marketing: Customer segmentation and sentiment analysis.
These industry-specific applications are studied in-depth in many course projects, showcasing how SageMaker can be adapted across domains.
Advantages of Using SageMaker
- Speed: Rapid development with minimal setup.
- Scalability: Automatically scales resources based on workload.
- Flexibility: Supports multiple frameworks and custom algorithms.
- Cost Efficiency: Pay-as-you-go pricing and support for spot instances.
Understanding these advantages is crucial for data professionals, especially those pursuing a data scientist course in Hyderabad, where cloud-native technologies are in high demand.
Challenges and Limitations
Despite its many strengths, SageMaker is not without challenges:
- Learning Curve: The breadth of features can overwhelm beginners.
- Cost Management: Misconfigured resources can lead to unexpected bills.
- Vendor Lock-in: Deep integration with AWS can make migration difficult.
A good course addresses these limitations, helping students learn how to navigate and mitigate them in practical scenarios.
How to Get Started
- Sign up for AWS and explore the free tier.
- Start a SageMaker Studio instance and create a project.
- Import or prepare your dataset using built-in tools.
- Choose your modeling approach—built-in, AutoPilot, or custom.
- Train and evaluate your model.
- Deploy the model and monitor its performance.
Conclusion
Amazon SageMaker has redefined how machine learning models are built, trained, and deployed at scale. Its robust suite of tools, seamless AWS integration, and flexibility across industries make it a leading choice for data professionals and organizations worldwide.
For students and professionals pursuing a course, gaining proficiency in SageMaker is an investment that pays off in career readiness and project success. From data preparation to model monitoring, SageMaker offers a streamlined, end-to-end solution that empowers users to innovate and deliver real-world AI applications with confidence.
ExcelR – Data Science, Data Analytics and Business Analyst Course Training in Hyderabad
Address: Cyber Towers, PHASE-2, 5th Floor, Quadrant-2, HITEC City, Hyderabad, Telangana 500081
Phone: 096321 56744